library(tidyverse)
## 図の中で日本語を使えるようにする
## フォントの設定はお好みで
## (Unix/Linux ではIPAexフォントのインストールが必要かも)
if (.Platform$OS.type == "windows") {
my_font <- "Yu Gothic"
} else if (capabilities("aqua")) {
my_font <- "HiraginoSans-W3"
} else {
my_font <- "IPAexGothic"
}
theme_set(theme_gray(base_size = 9,
base_family = my_font))3 乱数生成
今回の目標
- 乱数の作り方を覚えよう!
3.1 準備
必要なパッケージを読み込む。
3.2 乱数の生成
Rを使って乱数 (random numbers) を生成しよう。
3.2.1 コイン投げ
自分で決めた特定の対象から、ランダムにどれかを選びたいときは、sample() 関数を利用する。たとえば、この関数を使ってコイン投げを実行したいときは、
とする。size で何回選ぶか(何回コインを投げるか)を指定している。
これを何度か実行してみよう。
sample(coin, size = 1)[1] "裏"sample(coin, size = 1)[1] "表"sample(coin, size = 1)[1] "裏"sample(coin, size = 1)[1] "裏"sample(coin, size = 1)[1] "表"選ぶ回数を変えてみよう。
sample(coin, size = 2)[1] "裏" "表"もう一度やってみよう。
sample(coin)[1] "表" "裏"さらに、もう一度やってみよう。
sample(coin, size = 2)[1] "裏" "表"これを何度やっても、1回目が表なら2回目は裏、1回目が裏なら2回目が表になる。つまり、2回目のコイン投げはランダムではない。これは、sample() が決められた対象から1つずつ順番に選ぶという作業をしているためである。私たちが定義した coin の中身は「表」と「裏」の2つしかない。この2つから順番に選ぶ作業をすると、1つ目に表(裏)が出れば、2回目に残されているのは裏(表)だけなので、2回目がランダムではなくなってしまう。
試しに選ぶ回数を3回にしてみよう。
sample(coin, size = 3)Error in `sample.int()`:
! cannot take a sample larger than the population when 'replace = FALSE'エラーが出た。選ぶ対象が2つしかないのに3つは選べないのでエラーになる(エラーをよく読むと、そのように書いてある)。
したがって、sample() を使ってコイン投げを2回以上行うには、少し工夫が必要になる。sample() は私たちが特に指示をしないと非復元抽出(sampling without replacement)を行う。非復元抽出というのは、1度選んだものは選択肢から外すという選び方である。何度もコイン投げを繰り返すには、復元抽出 (sampling with replacement) を行えばよい。復元抽出では、1度選んだものも選択肢の中に戻す(選択肢として復元する)という選び方である。 sapmle() で復元抽出を実行するために、replace = TRUE という指示を加える。
sample(coin, size = 5, replace = TRUE)[1] "裏" "裏" "表" "表" "裏"これでコイン投げを複数回実行できる。
試しにコインを10回投げて、その結果を coin10 という名前で保存してみよう。(|> print()は結果を表示するためにつけているだけなので、結果を表示する必要がないならなくてもよい。)
[1] "表" "表" "表" "裏" "表" "表" "裏" "裏" "裏" "裏"10回のうち、表は何回出ただろうか?Rを使って数えてみよう。数えるために、以下の方法をとる。
- 特定のコイン投げ(1回目, 2回目, \(\dots\), 10回目)が表だったかどうか調べる
- 表の回数を数える
Rである特定の値(数または文字列)になっているか調べたいときは、== (二重等号)を使う。
Warning
= [等号1つ] は <- と同じで右側の内容を左側に保存してしまうので注意。
二重等号 ==は、「二重等号の左側は右側と同じかどうか」を調べ、同じときは TRUE(真)、異なるときは FALSE(偽)という答えを返す。簡単な例で確認してみよう。
a <- 2 # aに2を代入する
a == 2[1] TRUEa == 3[1] FALSEa == "裏" # 文字列と比べるときは文字列を引用符で囲む[1] FALSEこれを使って、上で行った10回のコイン投げが表だったかどうか確かめよう。
coin10 == "表" [1] TRUE TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE FALSEこのように、各回について、表 (TRUE) か裏 (FALSE) かを教えてくれる。
私たちは表が何回出たかを知りたいので、TRUE の回数を数えればいい。ここでは、10回しか投げていないので、自力で数えることもできるが、数が増えると数えるのは面倒である。そこで、Rを使って数える。Rでは TRUE と FALSE を数として扱うと、TRUE は 1、FALSE は0 とみなされる。したがって、TRUEの数を数えたいなら、上の結果を合計すればよい。合計は sum() で求められるので、次のようにする。
sum(coin10 == "表")[1] 5表は10回中5回だったことがわかる。
3.2.2 サイコロ投げ
同じ関数を使って、サイコロ (die) 投げを実行してみよう。 まずは、サイコロを定義する。
die <- 1 : 6 # 1から6までの整数
# 以下のような書き方も可能
# die <- c(1, 2, 3, 4, 5, 6)
# die <- seq(from = 1, to = 6, by = 1)これを復元抽出すれば、サイコロ投げを何度も行える。100回投げてみよう。
die100 <- sample(die, size = 100, replace = TRUE)3は何回出ただろうか?
sum(die100 == 3)[1] 1414回出たことがわかる。
ここまでは、「正しいコイン (a fair coin)」や「正しいサイコロ (a fair die)」を想定してきたが、特定の目が出やすいサイコロ(やコイン)を使うこともできる。「1が出る確率だけ他の目の4倍」というサイコロを1,000回投げてみよう。そのために、prob で各目が出る比率を指定する(確率を指定してもよい)。
1が何回出たか確かめてみよう。
sum(unfair1000 == 1)[1] 4411,000回のうち、441回1の目が出たことがわかる。
このように、それぞれの選択肢が選べる確率を自由に設定して実験することができる。
また、選ぶ対象も自由に設定できる。たとえば、
[1] "高知工科大" "高知工科大" "高知工科大" "高知工科大" "高知大"
[6] "高知県立大"のようなこともできる。
実習課題 (1)
- 1から6までの目がある「正しい」サイコロを2個振るという作業を1,000回繰り返し、出た目の合計が9になる回数を数えてみよう。
- 「正しくない」コイン(表が出る確率が0.5ではないコイン)を500回投げ、表が出た回数を数えよう。表が出る確率は自由に設定してよい(ただし、0, 0.5, 1 を除く)。
3.3 確率分布からの乱数生成
Rでは、代表的な確率分布から乱数を生成することが可能である。基本的には、 r(randomの頭文字)と、分布名の最初の数文字を組み合わせた関数を使う。
3.3.1 一様分布
一様分布 (uniform distribution) からの乱数生成には、runif() を使う。この関数では、以下の3つの引数(ひきすう)を指定する。
-
n: 生成する乱数の個数(必ず指定する) -
min: 最小値(指定しないと 0 に設定される) -
max: 最大値(指定しないと 1 に設定される)
Note
時計のように1から12(12は0とも考えらえる)の数字が書いてあるような円盤の上でランダムにルーレットを回すことを考える。そうすると、0から12の間のどの位置にルーレットが止まる確率も等しいと考えられる。このような状況を、最小値が0で最大値が12の(連続な)一様分布(連続一様分布; continuous uniform distribution)で表すことができる。このルーレットを100回使ってみよう。
a1 <- runif(n = 100, min = 0, max = 12)結果をヒストグラムにしてみよう。
df1 <- tibble(a1) # 結果をデータフレーム (tibble) に入れる
h1 <- ggplot(df1, aes(x = a1)) +
geom_histogram(binwidth = 1,
boundary = 0,
fill = "royalblue",
color = "black") +
labs(x = "時計盤上のルーレットからの乱数",
y = "度数") +
scale_x_continuous(breaks = 0 : 12) # x軸の目盛を調整
plot(h1)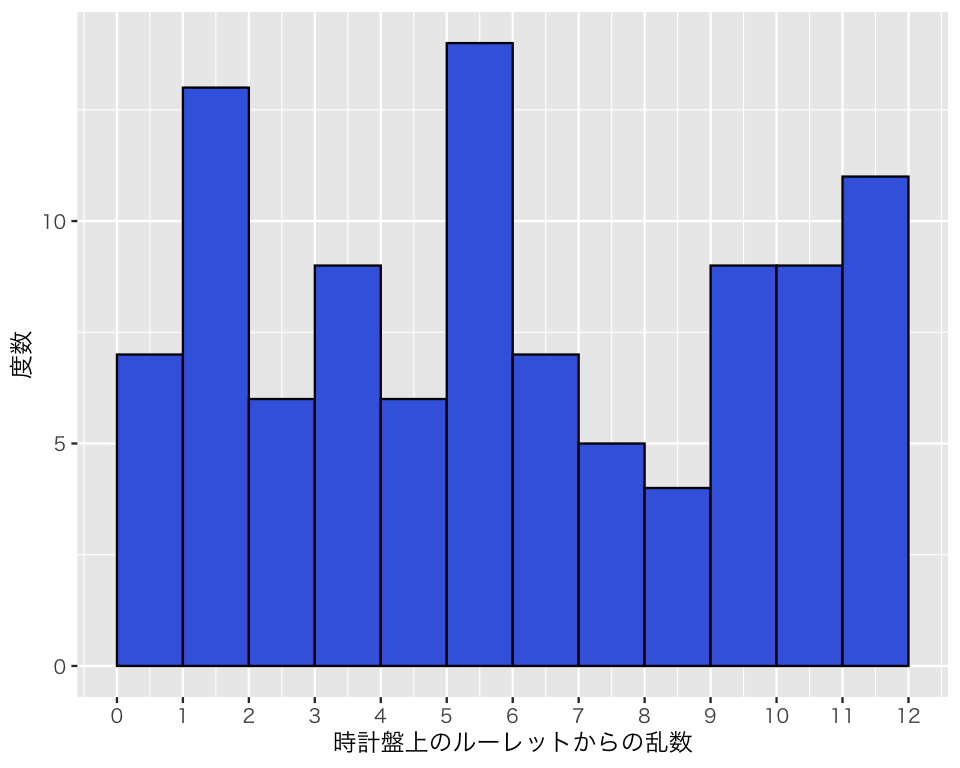
乱数の個数を増やしてみよう。
a2 <- runif(n = 10000, min = 0, max = 12)
df2 <- tibble(a2)
h2 <- ggplot(df2, aes(x = a2)) +
geom_histogram(binwidth = 1,
boundary = 0,
fill = "royalblue",
color = "black") +
labs(x = "時計盤上のルーレットからの乱数",
y = "度数") +
scale_x_continuous(breaks = 0 : 12) # x軸の目盛を調整
plot(h2)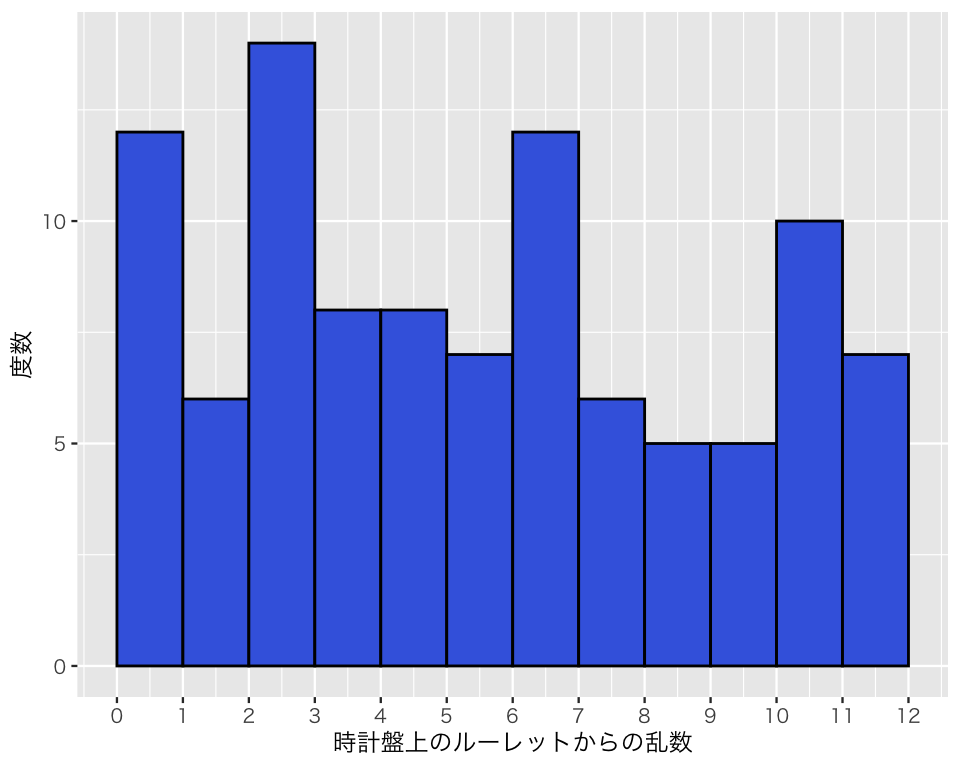
連続ではない一様分布(離散一様分布; discrete uniform distribution)からの乱数は、上で使った sample() で生成することができる。「正しいサイコロ」投げは、「1から6までの整数の(非連続な)一様分布」である。
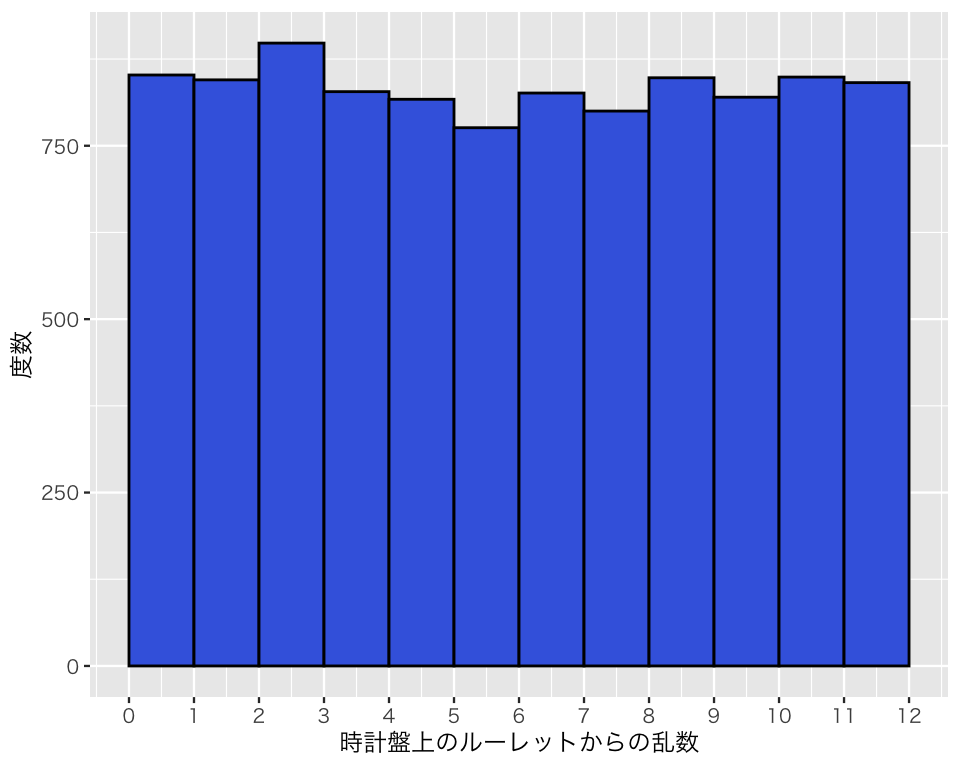
3.3.2 二項分布
コイン投げの結果は、表か裏の2パタン(通常、「成功」と「失敗」と呼ばれる。コイン投げでは、表と裏のどちらを成功と呼んでもよいが、ここでは表を成功、裏を失敗としておく)しかない。また、同じコインを何度か投げることを繰り返すとき、1回1回のコイン投げで表が出る確率は一定であると考えられる。
このように、結果が成功と失敗の2種類のみで、成功確率が \(\theta\) で一定(したがって、失敗確率は “\(1-\theta\)” で一定)であるような試行を \(N\) 回繰り返したとき、その成功回数の分布を、「試行回数 \(N\) で成功確率 \(\theta\) の二項分布 (binomial distribution)」と呼ぶ。
理論的には、二項分布の平均値(期待値)は \(N \theta\)、分散は \(N \theta (1 - \theta)\) になる。したがって、標準偏差は \(\sqrt{N \theta (1 - \theta)}\) になる。また、最小値は0(1ではないので注意)、最大値は \(N\) である。
たとえば、「試行回数5で成功確率0.3の二項分布」の平均値は\(5 \cdot 0.3 = 1.5\)、分散は \(5 \cdot 0.3 (1 - 0.3) = 1.05\)、標準偏差は \(\sqrt{1.05} \approx 1.02\) である(「\(\approx\)」は「ほぼ等しい」という意味)。最小値は0、最大値は5である。 この分布は、次の図のような形をしている。
sample() を使わずに、Rでコイン投げを実行してみよう。Rで二項分布に従う乱数を生成する関数は、rbinom() である。この関数で指定しなければならない引数(ひきすう)は以下の3つである。
-
n:実験の回数 -
size: 試行回数(0以上の(非負の)整数) -
prob: 成功確率(コイン投げで表が出る確率。0以上1以下)
たとえば、rbinom(n = 8, size = 10, prob = 0.4 ) とすると、「表が出る確率が0.4のコインを10回投げる」という実験を8回実行する。
rbinom(n = 8, size = 10, prob = 0.4)[1] 4 2 7 5 4 2 3 6結果として、8つの数字が表示されるが、それぞれの数字が、1回ごとの実験(コインを10回投げる)で表が何回出たかを表している。
Warning
この数は乱数 (random numbers)、つまり、Rによってランダムに生み出された数字なので、人によって異なる数字が得られるはずで、このWebページと同じ数字が出るとは限らない。
試しにまったく同じ関数をもう一度実行すると、違う数が得られる。
rbinom(n = 8, size = 10, prob = 0.4)[1] 4 3 6 3 6 2 3 4表が出る確率が0.5のコインを使って、1回のコイン投げ実験を1回だけ実行するには、
rbinom(n = 1, size = 1, prob = 0.5)[1] 1とする。0と出れば表が0回出た(つまり、裏が出た)ということであり、1ならば表が出たということである。何度か試してみよう。
rbinom(n = 1, size = 1, prob = 0.5)[1] 1rbinom(n = 1, size = 1, prob = 0.5)[1] 0rbinom(n = 1, size = 1, prob = 0.5)[1] 1rbinom(n = 1, size = 1, prob = 0.5)[1] 0rbinom(n = 1, size = 1, prob = 0.5)[1] 1表が出る確率が0.5のコインを使って、1回のコイン投げ実験を10回まとめて実行するには、次のようにする。
rbinom(n = 10, size = 1, prob = 0.5) [1] 1 0 0 0 1 0 1 0 1 1実習課題 (2)
- 3つの引数の値を変えて、様々な条件で二項分布からの乱数生成を試してみよう!
3.3.3 正規分布
正規分布 (normal distribution) からの乱数生成には、rnorm() を使う。この関数では、以下の3つの引数(ひきすう)を指定する。
-
n: 生成する乱数の個数(必ず指定する) -
mean: 正規分布の平均値(指定しないと 0 に設定される) -
sd: 正規分布の標準偏差(指定しないと 1 に設定される)
平均と標準偏差を指定しないと、平均が0で標準偏差が1の正規分布、すなわち標準正規分布からの乱数生成が行われる。
標準正規分布から100個の乱数を生成してみよう。
b1 <- rnorm(n = 100)作った乱数をヒストグラムにしてみよう。
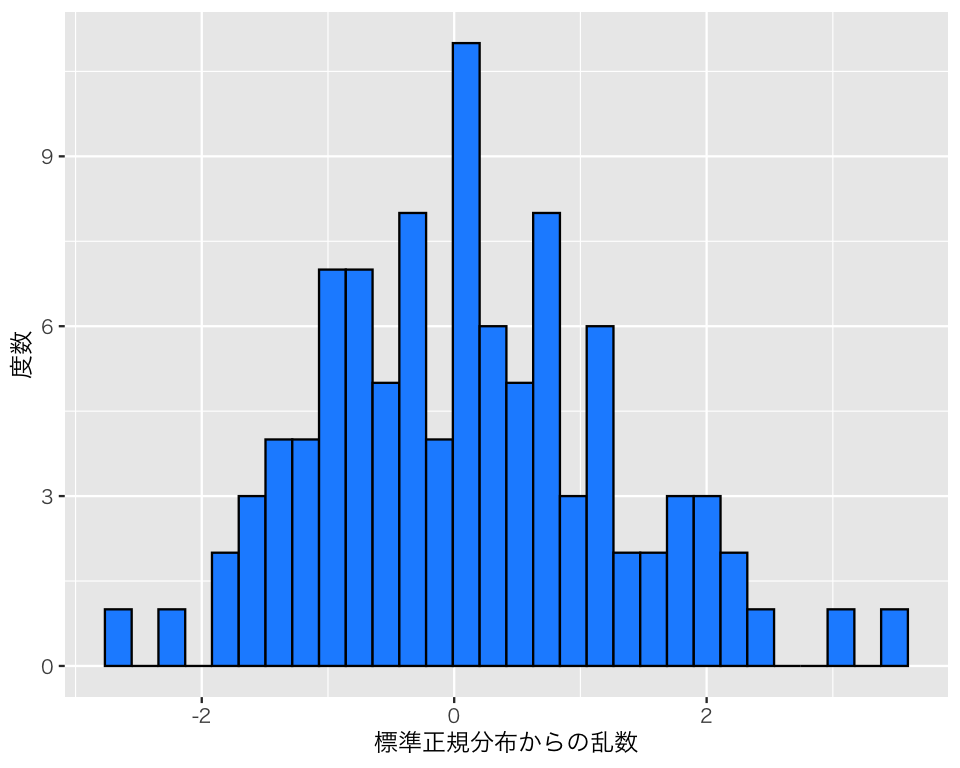
正規分布に見えるだろうか? 乱数の平均値と標準偏差を計算してみよう。
元の分布の平均値と標準偏差と比べると、どんなことが言えるだろうか?
乱数の数を増やして同じことしてみよう。
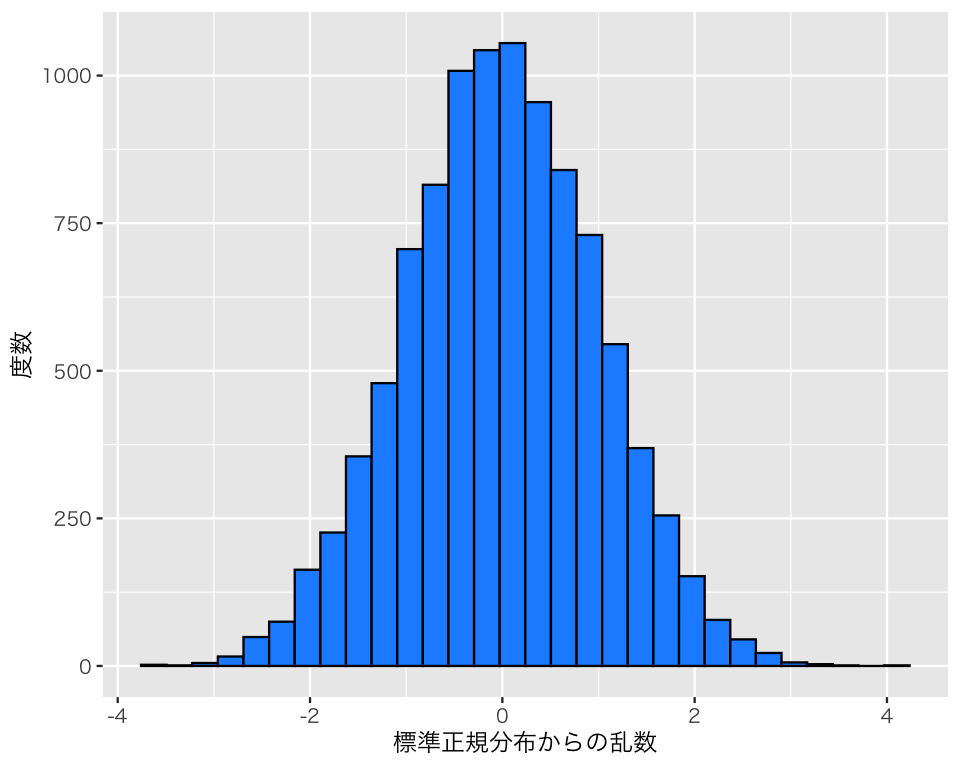
今度はどうだろうか?
乱数の平均値と標準偏差を計算してみよう。
元の分布の平均値と標準偏差と比べると、どんなことが言えるだろうか?
実習課題 (3)
- 平均が10, 標準偏差が4の正規分布から乱数を1,000個生成し、結果をヒストグラムにしてみよう。また、乱数の平均値と標準偏差を計算し、元になった分布と比べてみよう。